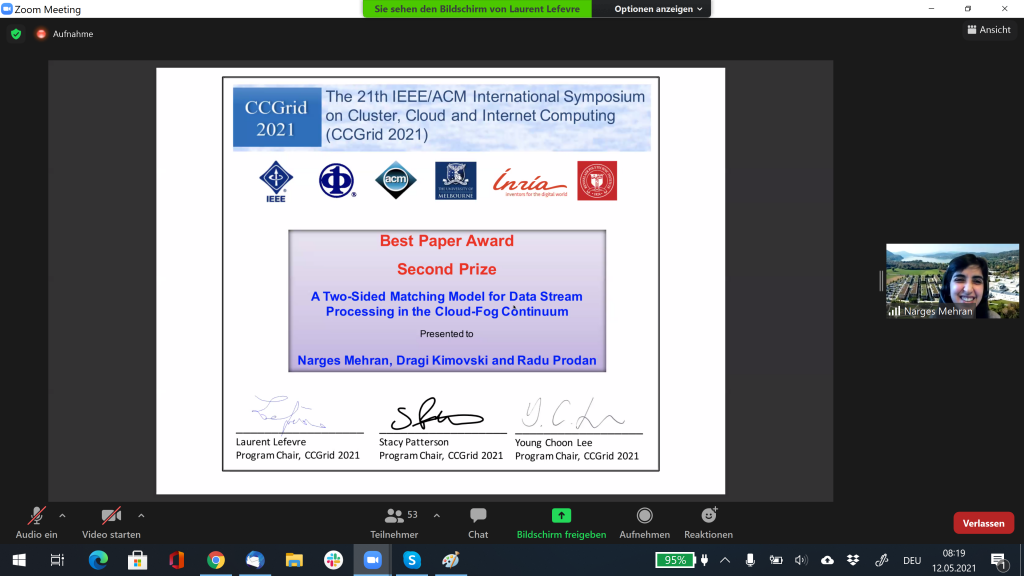
Paper accepted in 17th IEEE eScience conference
Conference: https://escience2021.org/
Title: Where to Encode: A Performance Analysis of x86 and Arm-based Amazon EC2 Instances
Authors: Roland Mathá, Dragi Kimovski, Anatoliy Zabrovskiy, Christian Timmerer and Radu Prodan
Abstract: Video streaming became an undivided part of the Internet. To efficiently utilise the limited network bandwidth it is essential to encode the video content. However, encoding is a computationally intensive task, involving high-performance resources provided by private infrastructures or public clouds. Public clouds, such as Amazon EC2, provide a large portfolio of services and instances optimized for specific purposes and budgets. The majority of Amazon’s instances use x86 processors, such as Intel Xeon or AMD EPYC. However, following the recent trends in computer architecture, Amazon introduced Arm based instances that promise up to 40% better cost performance ratio than comparable x86 instances for specific workloads. We evaluate in this paper the video encoding performance of x86 and Arm instances of four instance families using the latest FFmpeg version and two video codecs. We examine the impact of the encoding parameters, such as different presets and bitrates, on the time and cost for encoding. Our experiments reveal that Arm instances show high time and cost saving potential of up to 33.63% for specific bitrates and presets, especially for the x264 codec. However, the x86 instances are more general and achieve low encoding times, regardless of the codec.